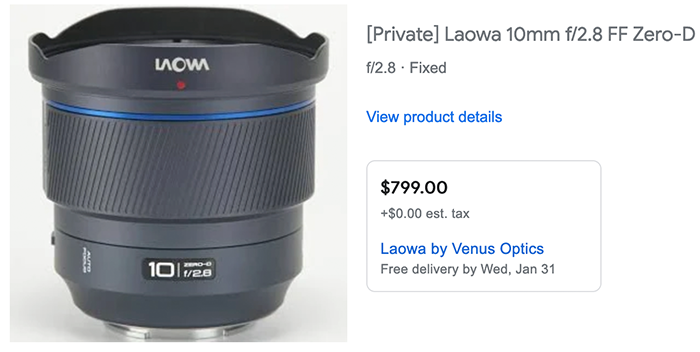
The price of the 10mm f/2.8 FF AF lens has been leaked through google shop. This contains a link to this “private” Venus Optics URL: https://www.venuslens.net/product/private-laowa-10mm-f-2-8-ff-zero-d/ref/5/. The lens is coming to your home on Jan 31.
I guess official preorders will open any time soon!
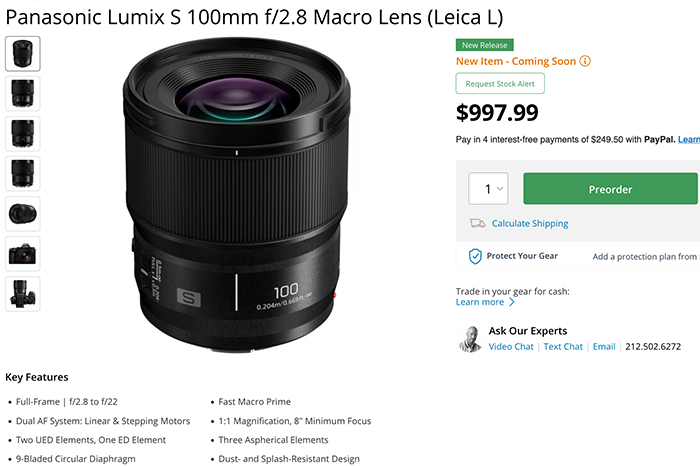
So my rumors were spot on and we got the new 100mm macro lens! You can preorder it now at BHphoto. Adorama. Amazon. WexUK.
Press text:
LAS VEGAS, Jan. 8, 2024 /PRNewswire/ — Panasonic is pleased to introduce the brand new LUMIX S 100mm F2.8 MACRO (S-E100) lens based on the L-Mount system standard. Compact and lightweight to match the camera body, the S-E100 lens joins the LUMIX S Series lineup which is designed to address the demand for accessible yet professional grade photography gear.
With a new optical design and a newly developed Dual Phase linear motor, the S-E100 is the world’s smallest and lightest medium-telephoto fixed focal length macro lens, weighing approximately 298 grams. It boasts high resolution, stunning bokeh unique to macro lenses, excellent depth in expression, and fast focusing in a chassis matched to our existing F/1.8 series of lenses. At the same time, its compact nature ensures excellent mobility outdoors and in other shooting locations.
In addition to close proximity photography, the S-E100 also produces impressive portraits and images unique to medium-telephoto lenses, with support for fast autofocusing and bright F/2.8 aperture. Following increased demand for video capabilities, the S-E100 produces high-quality video content through silent operation with optically corrected focus breathing. This is due to the newly developed linear focus motor and micro-step aperture control. These features allow for smooth exposure change and the ability to choose between linear or nonlinear focus ring settings.
By providing cutting edge, improved performance and mobility for camera enthusiasts and professionals, LUMIX aims to create a new digital mirrorless camera market.
Main Features
1. The World’s Smallest and Lightest2 Medium-Telephoto Fixed Focal Length Macro Lens
A more compact structure thanks to an optical design, featuring a new Double Focus System, three aspherical lenses and a newly developed Dual Phase Linear Motor with a new actuator.
Suitable for use in a wide range of situations due to its excellent mobility, whether it’s close proximity photography, natural photos and portraits, or faster paced action, unique to medium-telephoto lenses.
2. High Resolution and Outstanding Photographic Performance
Boasts high resolution and elaborate photographic performance in every area, from the center of the image to its edges.
Captures every detail of the subject while creating bokeh unique to medium-telephoto macro lenses.
3. Optimal Video Functionality for Video Production
Offers silent operation thanks to a newly developed Dual Phase Linear Motor.
Suppresses focus breathing, in which the angle of view changes, caused by movements in the focus position.
4. Fast Autofocus performance for expanded capabilities
Newly developed Dual Phase Linear Autofocus motor enables speed and precision for faster action tracking in both Photo and Video uses.
Ultra-High precision manual focus sensor allows for unparalleled manual focus precision, even when working at 1:1 macro.
5. Unified Design and rendering
Designed to match our exiting F/1.8 series of lenses, the S-E100 allows photographers and videographers to maintain a unified experience from 18mm – 100mm with matched size, filter threads, and similar weight.
Image renders has been tuned within this series of lenses to produce unified color regardless of which lens is used.
The LUMIX S-E100 lens will be available at valued channel partners at the end of January 2024 for $999.99 MSRP.
As you know there is an official collaboration between Panasonic and DJI when it comes to Lidar AF. Here are some interesting early videos about how it works:
Panasonic announced this new AI tech. Let’s see when this will be implemented in future Lumix cameras!
Panasonic HD Develops Image Recognition AI With New Classification Algorithm That Can Handle Multimodal Distribution
Osaka, Japan – Panasonic Holdings Co., Ltd. (hereinafter referred to as Panasonic HD) has developed an image recognition AI with a new classification algorithm that can handle the multimodal nature of data derived from subject and shooting conditions. Experiments have shown that the recognition accuracy exceeds that of conventional methods.
Image recognition AI recognizes objects by classifying them into categories based on their appearance. However, there are many cases when even objects belonging to the same category, such as “train” or “dog”, are classified under subcategories such as “train type” or “dog breed”, having very different appearances. Furthermore, there are many cases in which the same object can appear to look different due to differences in shooting conditions such as orientation, weather, lighting, or background. It is important to consider how best to deal with such diversity in appearance. In order to improve the accuracy of image recognition, research to this point has been carried out with the aim of achieving robust image recognition that is not affected by diversity, and classification algorithms have been devised to find similarities within subcategories and features common to objects in a given category.
As AI continues to be deployed in a variety of settings and a large number of diverse images are being handled, the limits of the approach of “finding common features” have become apparent. In particular, when there are subcategories with different appearance tendencies within the same category (multimodal distribution), AI often has trouble successfully recognizing such objects as being in the same category, resulting in a decrease in recognition accuracy.
Therefore, our company has focused on taking advantage of differences in appearance and developed a new classification algorithm that captures the diversity of images using a two-dimensional orthonormal matrix. Using a benchmark dataset*1, we demonstrated that it is possible to perform highly accurate image classification even on data with a multimodal distribution, which is difficult for AI.
This technology is a result of the research of REAL-AI*2, the Panasonic Group’s AI expert training program, and was accepted to the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2024), a top conference in the computer vision field. A presentation will be made at the plenary conference in Hawaii, USA, which will be held from January 4 to January 8, 2024.
Panasonic HD will promote the research and development of AI technology that accelerates its social implementation while also focusing on training top AI experts.
Overview:
The applications of image recognition technology are increasing, and the technology is expanding into situations where it has not been used before. As its applications expand beyond areas where it was easier to apply, there is a need to deal with objects in the same category that can appear in a variety of ways, something that conventional AI has difficulty with.
In the conventional deep learning framework, an AI model basically learns that things that look similar belong to the same categories. But in recent years, in order to improve classification performance, it has become common to significantly increase the number of data and variations in appearance during its learning process. This makes it possible to determine that the given objects fall into the same category, even if the objects appears completely different depending on factors like the shooting orientation, lighting, and background. For this reason, attention has been focused on how to have AI successfully learn the essential features that are common to the target objects without being distracted by the variety of appearances contained in large amounts of data.
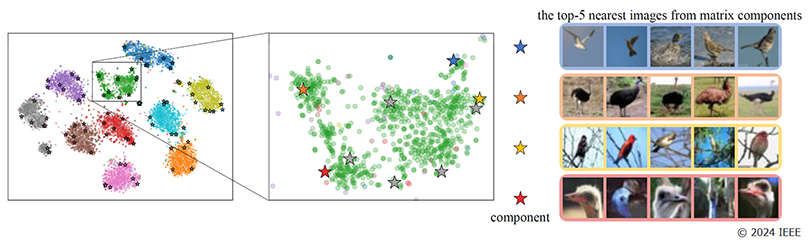
The distribution of appearances within a category is actually not uniform. Within the same category, there are multiple subcategories with multiple different trends in appearance (multimodal distribution). For example, in the “Birds” category shown in Figure 1, there are groups of images of the same bird with different tendencies, such as “birds flying in the sky”, “birds in the grassland”, “birds perched in trees”, and “bird heads”. Each of these images contains rich information about the object. If we focus on the essential features, we end up throwing away the diverse information that the images contain. Therefore, we have developed an algorithm that actively utilizes information about the various ways in which objects appear to improve AI’s ability to recognize images with multimodal distribution, which is difficult for AI. In order to continuously capture the distribution of features, we expanded the weight vector of the classification model, which has traditionally only been a one-dimensional vector, to a two-dimensional orthonormal matrix. This allows each element of the weight matrix to represent a variation of the image (differing background colors, object orientation, etc.).
As a result of this experiment*1 on a benchmark dataset, this method has shown that it is possible to identify the edge of a group of features that should allow the AI to classify the same object (the star mark indicates the edge of the “bird” category captured by this method) as shown in Figure 1, by introducing a classifier that can continuously capture image features that are included in extremely diverse categories that look like “birds”.
As a result, as shown in Figure 2, even for categories like “bus” and “streetcar”, which are close in appearance and difficult to classify as separate, our algorithm was able to find images that belong to the same category without being confused by other vehicles that look similar.
Due to the algorithm being simple, when adding it to a general deep learning-based image recognition model (ResNet-50), the memory increase is only about 0.1% in practical use (10 classes). It is expected that recognition accuracy and explainability can be improved with only a small increase in memory usage.
This method can perform image recognition that smoothly captures the characteristics of the same object that appears in various ways, which is something that is difficult for conventional AI to accomplish. This is expected to make contributions especially in situations where advanced image understanding is required at sites with a variety of perspectives, such as those relating to mobility, manufacturing, and robotics.
Panasonic HD will continue to accelerate the social implementation of AI technology and promote the research and development of AI technology that will help customers in their daily lives and work.
*1 Classification task for image recognition benchmark dataset CIFAR-10/100, ImageNet.
*2 An in-house research group organized across the entire group to lead the Panasonic Group’s cutting-edge AI research and development by fostering top human resources who can quickly deploy cutting-edge technology and create value. Under the guidance of Professor Tadahiro Taniguchi, a professor at Ritsumeikan University and an employee of Panasonic HD, and Professor Takayoshi Yamashita of Chubu University, many members, from young people to experts, took on the challenge of competing at top conferences, and many papers were accepted.
*3 Wang, W., Han, C., Zhou, T. and Liu, D.: Visual Recognition with Deep Nearest Centroids, The Eleventh International Conference on Learning Representations (2023).